Regression¶
Assume that we have dataset \(\mathcal{D}={(\mathbf{x}_1, y_1,...,(\mathbf{x}_n,y_n)}\) where \(\mathbf{x}_i\in\mathbb{R}^m\) and \(y_i\in\mathbb{R}\), where \(\mathbf{x}_i\) consists of \(m\) measurements or attributes associated with the \(i\)-th observation and \(y_i\) is the \(i\)-th target variable which is some real number. Then we are interested in learning some functional map that maps from our observation space to our target space i.e. \(\mathcal{X}\rightarrow\mathcal{Y}\). There are a multitude of assumptions we could make about defining the best \(f\) but the most popular is to assume \(f\) is the curve of best fit through our data and the noise present is Gaussian. Mathematically we can define the functional relationship to be
where \(\boldsymbol{\theta}\) are the parameters for our functional map \(f\) and \(\epsilon_i\) is some random Gaussian noise. The reason why we can assume that noise is present is because we often may not have all the information in \(\mathbf{X}\) to construct \(\mathbf{y}\) or our proposed function \(f\) may be simpler than the true function \(f^{*}\) and so we are finding the best simpler model that fits the more complicated dataset.
From Eq. (1), we can say that our predictor for \(y_i\) is \(\mathbb{E}[f(\mathbf{x}_i;\boldsymbol{\theta}) + \epsilon_i] = \mathbb{E}[f(\mathbf{x}_i;\boldsymbol{\theta})]\). For notational convenience let us denote \(\mu(\mathbf{x}_i;\boldsymbol{\theta}) = \mathbb{E}[f(\mathbf{x}_i;\boldsymbol{\theta})]\), and assume that our function \(f\) is deterministic i.e. a strict one to one map. We can then say that
that is, our target variable given an associated distribution follows an independent and identically distributed Gaussian with mean \(\mu(\mathbf{x}_i,\boldsymbol{\theta})\) and variance \(\sigma^2\). To visualise the relationships between the variables we have the below.
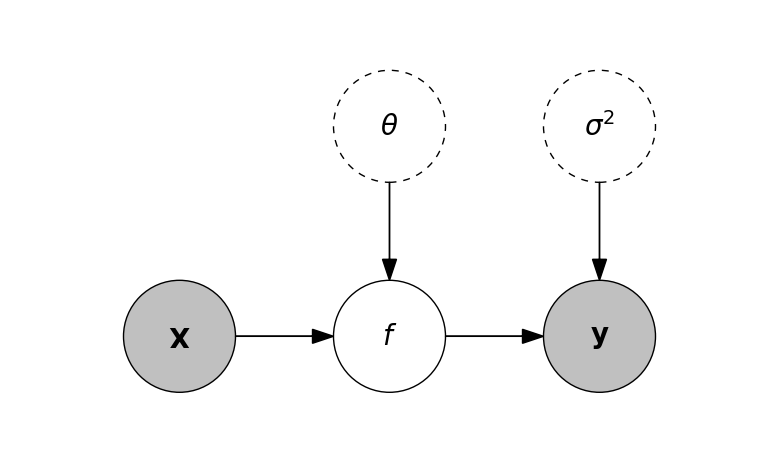
Fig. 39 Graphical model representation of the regression problem. Dotted circles are the unknowns of interest, shaded circles are the data, and regular circles are functions.¶
Writing the conditional probability density of Eq. (2) we yield
Assuming that each of the \(n\) observations are independent, we can state
Note
The notation used in Eqs. (6-8) all mean the same thing.
For simplicity, let \(\mathbf{z} = \mathbf{y} - \boldsymbol{\mu}(\mathbf{X};\boldsymbol{\theta})\) and to simplify further assume that \(\mathbf{z}\in\mathbb{R}^{3}\) i.e. \(\mathbf{z} = [z_1,z_2,z_3]\), then:
The jump from Eq. \(\eqref{eq:sum}\) to Eq. \(\eqref{eq:transpose}\) is now explained. Eq. \(\eqref{eq:norm}\) comes from the definition of a vector norm.
The probability distribution \(p(\mathbf{y}_i\mid\mathbf{x}_i,\boldsymbol{\theta},\sigma^2)\) stated in Eq. \(\eqref{eq:normal-pdf}\) indicates a distribution over \(\mathcal{Y}\) with the most probable value to be \(\mu(\mathbf{x}_i;\boldsymbol{\theta})\). Likewise, for the entire dataset, the most likely set of values associated with \(\mathbf{X}\) is \(\boldsymbol{\mu}(\mathbf{X},\boldsymbol{\theta})\). In plain english, the left hand side of Eq. \(\eqref{eq:likelihood}\) is the likelihood (or probability) that we would observe \(\mathbf{y}\) if we started from \(\mathbf{X}\) and used Eq. (1) to generate \(\mathbf{y}\). If the probability is low then we have a poor functional map \(f\) and similarly, if we the probability is high then we have a good functional map \(f\). As the function log just converts the probability space \((0,1)\) to the log probability space \((-\infty,0)\), we can choose to maximise the log probability instead. This is often done in practice as the resulting math is much easier and maximising the log probability also maximises the probability.
To maximise Eqs. (\(\ref{eq:sum}\)-\(\ref{eq:norm}\)) (all the same expression) with respect to \(\boldsymbol{\theta}\), we can consider all other variables constants and simply ignore them for the optimisation step. We can see that maximising the log probability is equivalent to minimising
To minimise \(\mathcal{L}(\boldsymbol{\theta};\mathbf{X},\mathbf{y})\), we can consider the Jacobian (first derivative) and perform gradient descent,
where \(\odot\) denotes element-wise multiplication.
Note
Differentiating the loss function.
\(\nabla_\theta \mathcal{L}(\theta;\mathbf{X},\mathbf{y})\) means the vector differential of \(\mathcal{L}(\theta;\mathbf{X},\mathbf{y})\) with respect to \(\theta\). Suppose that there are three parameters \(\theta_1,\ \theta_2 \text{ and } \theta_3\), and we want to find the differential of \(\mathcal{L}((\theta_1, \theta_2, \theta_3);\mathbf{z}) = ||\mathbf{z}(\theta_1,\theta_2,\theta_3)||_2^2\) with respect to \(\theta_1\) where \(\mathbf{z} = [z_1,z_2,z_3]\) then:
where \(\odot\) denotes element-wise multiplication.
If our functional map \(f\) is linear, we can solve Eq. \(\eqref{eq:grad}\) directly and this is called linear regression, if it is non-linear, we typically cannot solve it and have to resort to gradient descent. For all deterministic functional maps \(f\), this underlying theory will apply. If the functional map \(f\) is stochastic i.e. has an underlying distribution a more general set of assumptions will have to be made around the variance \(\sigma^2\) attributed to the distribution of \(\mathbf{y}\) as there will be covariances introduced. See the gaussian process as an example.